Data Reliability, Machine Learning
AI Readiness Starts With Data Contracts

Team Qualdo
16 Mar 2026
The 2026 guide to stable inputs, enforceable guarantees, and trustworthy AI output
AI reliability is a data agreement problem before it’s a model problem.
When AI results feel inconsistent, teams often reach for better prompts, bigger models, or more fine-tuning. In practice, the most common root cause is simpler: the inputs are not stable or explainable. Data contracts fix that by defining what data means, what shape it must have, what quality is guaranteed, and how change is managed-so AI pipelines stop inheriting “data chaos.”
Why AI readiness breaks in real life
AI systems fail quietly when upstream data changes quietly.
A feature can keep the same column name while its business meaning drifts. Producers can add or remove fields without notifying consumers. Freshness can slip for hours and nobody notices until the agent starts making strange decisions. In classic analytics, these issues are painful. In AI, they become risk: retrieval indexes the wrong truth, models train on shifting labels, and agents execute actions based on corrupted assumptions.
AI amplifies small defects because it turns many weak signals into confident output. Without explicit input guarantees, the system can’t tell the difference between “new valid reality” and “broken pipeline.”
Common failure mode
A key column remains the same name but changes meaning.
Example: status used to mean “payment settled” and now means “order confirmed.”
Dashboards look fine. Models and agents silently degrade. Nobody gets an alert because nothing “crashed.”
What a data contract is in 2026
A data contract is a formal agreement between the producer of a dataset and the teams or systems that depend on it.
It specifies the dataset’s shape and meaning, the quality guarantees, the reliability expectations, and the rules for change. In other words, it makes the dataset behave like a product with a clear interface instead of a loose artifact that evolves unpredictably.
In 2026, many teams express contracts using the Open Data Contract Standard (ODCS) because it gives a consistent structure for describing schema, semantics, quality expectations, SLAs, ownership, and governance in a machine-readable way. The standard itself is less important than the discipline: contracts must be easy to read, versioned, and enforceable.
What contracts are not
A contract is not a Confluence page that nobody maintains.
A contract is not a one-time schema snapshot.
A contract only earns the name when it can be validated and enforced.
Why contracts matter more in the AI era
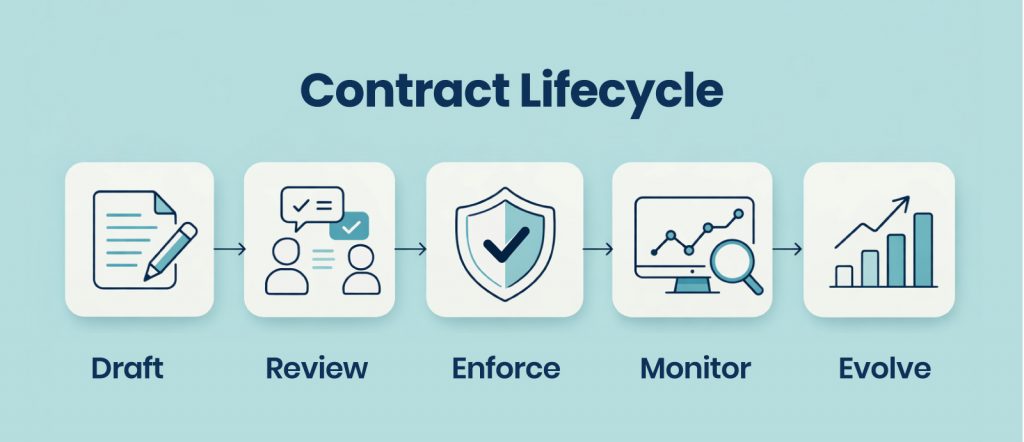
Before AI, a silent breaking change was often treated as an inconvenience. Someone fixed a pipeline, updated a dashboard, and moved on. AI changes the stakes.
AI needs repeatable, versioned inputs. If training data cannot be reproduced, you cannot diagnose drift with confidence. If RAG sources do not carry freshness and ownership guarantees, retrieval becomes “best effort” truth. If agents depend on tool data that can change without warning, safety becomes fragile.
Contracts shift the system from “data is whatever showed up today” to “data is a governed interface with expectations.” That shift is the foundation of AI readiness.
What a good contract contains
A good contract is short enough to maintain, specific enough to enforce, and clear enough that a new engineer can understand what the dataset represents.
At a minimum, every contract should include:
Identity and ownership: A clear dataset name, domain, an accountable owner, and a support path. If nobody owns it, nobody will protect it.
Schema and constraints: Types, required fields, keys, and constraints that make the dataset safe to consume.
Semantic definitions: A definition of the most important columns: IDs, timestamps, statuses, monetary fields, and key categories. This is where many “AI failures” actually begin.
Reliability expectations: SLAs such as freshness, completeness, latency, and availability. RAG and agent systems need these to decide what to trust and when.
Quality expectations: Rules that express what “healthy” means: null limits, uniqueness, validity ranges, and distribution expectations.
Change rules: Versioning, compatibility rules, deprecation windows, and a change log to keep consumers from being surprised.
Governance: Access classification, PII tagging, and usage expectations so compliance and auditability are built in from the start.
Contracts reduce ambiguity, not just errors
Many issues aren’t “wrong data.” They’re “unclear data.”
Contracts force meaning to be explicit, which is what AI systems desperately need.
Enforcement patterns that make this real in 2026
A contract only matters when it can block bad changes and surface drift early. Here are three patterns that teams actually succeed with.
Pattern A – Warehouse enforcement for curated tables
If your organization relies on curated warehouse models, enforce contracts at build time. When a contract specifies schema expectations and constraints, the pipeline should fail if the output does not match. This prevents “oops changes” from reaching downstream features, dashboards, and indexes.
This pattern is especially effective for analytics-to-feature pipelines because it catches breaking changes before they become model drift.
Pattern B – Streaming enforcement for events
Event-driven systems need safe evolution. The core requirement is compatibility over time so consumers do not break when producers ship changes. Schema validation and compatibility gates make producers accountable for change discipline and give consumers predictable evolution.
This is one of the highest ROI places to introduce contracts because silent event changes can corrupt many downstream systems at once.
Pattern C – Contract-as-code in CI/CD
This is the most scalable pattern in 2026. Contracts live in Git, change through pull requests, and get validated in CI. The pipeline lints contract structure, checks compatibility rules, and validates schema and quality expectations against the actual data environment.
Contract-as-code turns cross-team agreements into enforceable gates. It also creates a reliable audit trail of what changed, when, and why.
Common failure mode
Teams “write contracts” but never connect them to CI or runtime checks.
The docs look great, but production still drifts.
If the contract can’t fail a build or raise an alert, it isn’t protecting your AI.
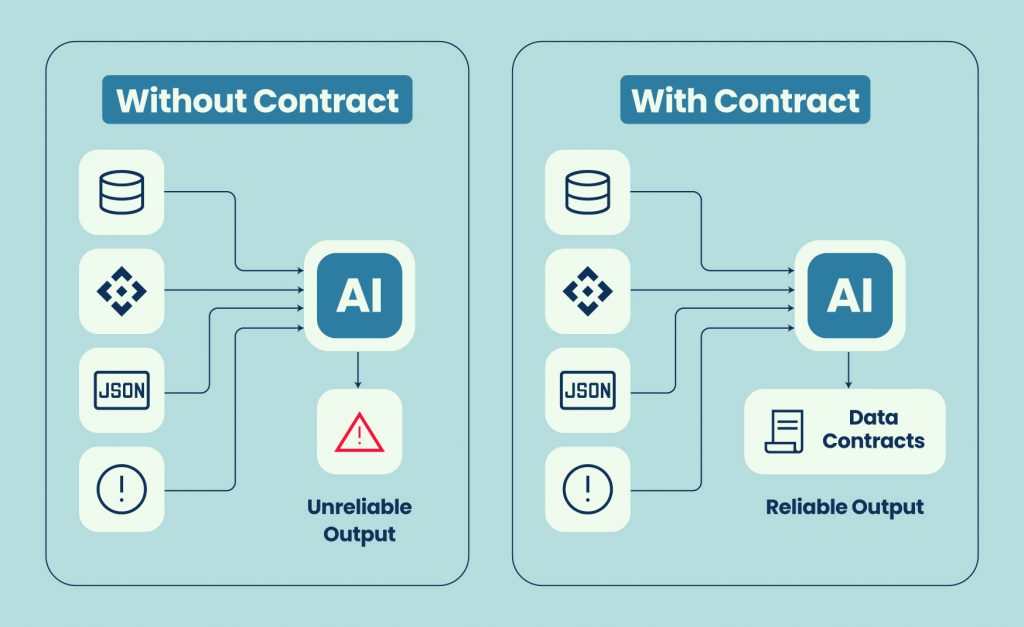
The AI readiness mapping: where contracts plug in
Data contracts become most valuable when you align them to your AI stack.
For training and feature pipelines, contracts stabilize feature meaning and enable reproducible training sets. This is critical for diagnosing drift and for repeating experiments with confidence.
For RAG systems, contracts turn “source documents” into governed sources of truth. Freshness guarantees and ownership make it possible to decide what to index, how often to refresh, and which sources are authoritative.
For agents, contracts help with tool and action safety. Agents don’t just answer questions. They act. If the data that drives actions can change silently, the agent’s behavior becomes unpredictable.
For compliance, contracts help answer the operational questions that matter: what data was used, when, under what classification, and with what guarantees.
Starter template you can paste into your repo
Keep the template simple, so adoption is easy, then tighten it over time.
Use these sections as your contract “shape”:
Metadata
Name, domain, description, tags
Ownership and support
Owner, steward, escalation path, support channel
Schema
Fields, types, constraints, primary keys
Semantics
Definitions for key columns, timestamp meaning, monetary meaning, enums and allowed values
Quality rules
Null limits, uniqueness rules, validity ranges, distribution expectations
SLA
Freshness, completeness, latency, availability, incident policy
Access and compliance
PII classification, permitted use, retention notes
Versioning and compatibility
Version, compatibility rules, deprecation policy, change log
Don’t over-engineer the first contract
Your first contracts should be readable in five minutes.
Start with meaning, ownership, and a few high-value guarantees.
Expand as you learn what actually breaks.
Adoption plan: the practical path that sticks
The fastest way to make this real is to start with the datasets that can hurt you.
Pick the top ten datasets that power revenue, risk, or AI. That usually includes feature tables, label sources, key event streams, and the sources used for retrieval.
Write contracts for those datasets first and assign real owners. Avoid shared ownership because it dilutes accountability. Add SLAs that reflect the business impact of staleness or incompleteness.
Then enforce contracts in two places. First in CI, to block breaking changes before they ship. Second, at runtime, to detect drift in freshness and quality while it’s still small.
Finally, make change management non-negotiable. Require version bumps, enforce compatibility gates, and use clear deprecation windows. The goal is not to prevent change. The goal is to make change safe.
Closing: AI readiness is a data agreement milestone
AI readiness isn’t a model milestone. It’s a data agreement milestone.
If your data can change without permission, your AI can’t be trusted. Data contracts set the baseline for stability, explainability, and repeatability across training pipelines, retrieval systems, and agents.
If you’re rolling out data contracts, the next challenge is continuous enforcement-proving SLAs, detecting drift, and monitoring contract compliance over time. Qualdo.ai helps teams operationalize reliability so contracts remain true in production, not just in documentation.
FAQs
Do I need a full standard like ODCS to start?
No. Start with a lightweight structure that covers ownership, semantics, and a few critical guarantees. A standard becomes useful when multiple teams need a shared format and automation benefits from consistency.
What’s the difference between a schema and a contract?
A schema describes fields and types. A contract includes schema plus meaning, quality expectations, SLAs, governance, and rules for safe change.
Where should I enforce contracts first?
Start where breakage hurts most and is easiest to gate: curated warehouse models or core event streams. Add CI checks early so breaking changes get blocked before they spread.
Will contracts slow teams down?
They slow down unsafe change. They speed up safe change. The net effect is usually faster delivery because teams spend less time firefighting downstream failures.
How do contracts help RAG and agents specifically?
RAG needs freshness, ownership, and trusted sources to avoid indexing stale or incorrect truth. Agents need reliable tool inputs so actions don’t become unpredictable when upstream data shifts.


