Data Observability, Data Reliability
How to Ensure Data Reliability for Predictive Analytics in 2025

Team Qualdo
23 Oct 2025
Former Facebook VP Julie Zhuo recently warned that many fast-growing AI startups are “flying on vibes,” scaling rapidly without a strong foundation in logging or analytics. It’s a timely caution for any data-driven enterprise. In predictive analytics, even the most sophisticated model can collapse under unreliable data.
In 2025, as over 65% of organizations actively adopt or explore AI in analytics, the reliability of data defines whether insights drive growth or chaos.
This article unpacks:
- Why reliability is the make-or-break factor for predictive analytics
- The core challenges shaping 2025
- How AI and observability are transforming reliability
- Real-world examples, practical roadmaps, and key pitfalls to avoid
Why Reliability Matters More Than Ever
Predictive analytics thrives on one assumption: that the data it consumes is accurate and stable. However, in practice, that assumption often breaks more frequently than most teams realize.
Data pipelines fail silently. Schema changes slip through unnoticed. Missing values and inconsistent keys quietly distort results. And when monitoring is weak, models begin to learn from corrupted inputs without anyone noticing, until their performance deteriorates.
Data reliability doesn’t actually refer to “clean data.” It’s the ongoing assurance that data remains accurate, consistent, fresh, and traceable across its entire lifecycle, from ingestion to decisioning.
Without it, predictive analytics becomes educated guessing.
The 2025 Reality Check
By 2030, AI infrastructure needs are projected to reach $2 trillion per year, yet Bain predicts an annual shortfall of $800 billion. This means that many analytics pipelines will be stretched to their limits, fragile, under-observed, and prone to errors.
At the same time, analytics ecosystems are becoming vastly more complex:
- Unstructured and multimodal data, text, images, sensor logs, and flood systems with unpredictable formats.
- LLM-based “Deep Research” frameworks merge reasoning with query optimization, cutting cost and runtime by up to 70%, but they depend on pristine inputs.
- Autonomous and agentic AI systems now act on data in real-time, magnifying the consequences of incorrect input.
The question is no longer we can scale analytics?
It is – Can we trust it at scale?
From Data Chaos to Data Confidence
Reliable data isn’t a product of chance; it’s engineered.
It begins with clarity, knowing what data should look like, where it comes from, and how it’s used. Schema contracts, validation checks, and alerting systems form the first line of defense.
Then comes visibility. Observability tools track drift, latency, and anomalies across the pipeline. Metadata catalogs and lineage graphs trace every transformation, ensuring that no change goes unaccounted for.
Finally, reliability demands resilience. When upstream data breaks, systems shouldn’t crash; they should degrade gracefully. Backup queues, fallback defaults, and circuit-breaker patterns prevent cascading failures.
True reliability isn’t perfection; it’s the ability to fail safely and recover quickly.
The Human Side of Reliability
Data reliability isn’t just an engineering discipline; it’s a cultural value.
Teams that prioritize velocity over validation often trade short-term speed for long-term fragility.
Reliability requires consistency, accountability, and shared ownership. It thrives in organizations that value testing, documentation, and feedback loops as much as delivery deadlines.
As self-service analytics continue to grow, this becomes even more vital. When business users query data directly, every dataset becomes a decision surface, and every inconsistency, a potential risk. Governance must scale alongside accessibility.
AI and the Future of Reliable Analytics
The tools designed to solve reliability gaps are now becoming intelligent themselves.
Emerging systems, such as semantic operator frameworks, can interpret data logic, detect drift, and even suggest corrections. AI-driven observability platforms use predictive models to spot anomalies before they impact downstream results.
Meanwhile, the Model Context Protocol (MCP), a new open standard, enables AI systems to access data sources securely and contextually, preventing errors and misuse.
The next generation of reliability will be AI-augmented, self-healing, and proactive, ensuring not only that data is accurate, but also that systems recognize when it’s not.
Lessons from the Field
Real-world examples illustrate how reliability makes or breaks analytics outcomes:
- Financial Trading:
The London Stock Exchange (LSEG) integrates AI into risk and forecasting models. A single corrupted data feed could distort thousands of trades; reliability is mission-critical in this context. - Autonomous Auditing:
AppZen’s bots for finance and auditing depend on validated data; without it, false positives or missed fraud could undermine trust. - Cross-Domain Ecosystems:
With Databricks investing $250M in India’s Data + AI Academy, regional enterprises are scaling analytics fast; those that embed reliability early will sustain performance longer. - Startups Scaling Too Fast:
As Zhuo cautioned, skipping foundational analytics leaves teams blind to basic questions, such as customer churn and growth drivers, as well as the hidden costs of unreliability.
Your Roadmap to Reliability Maturity
Building reliability isn’t a one-step fix; it’s a continuous journey. Here’s a progressive path to follow:
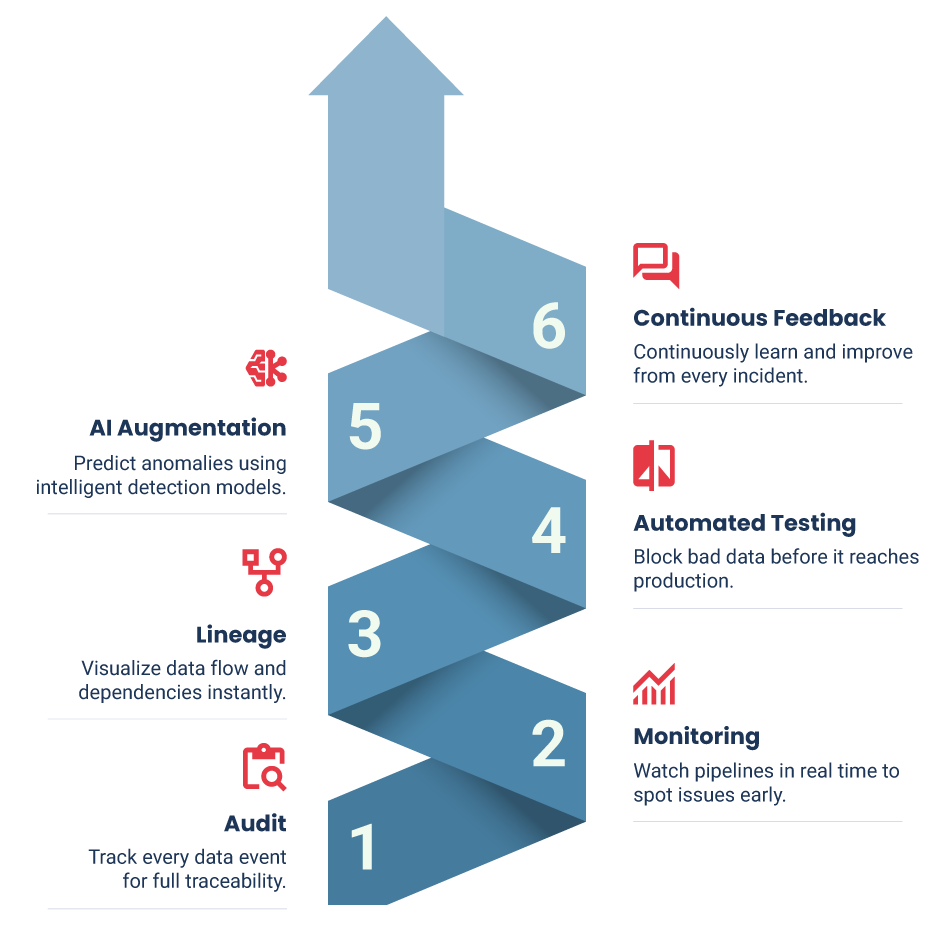
- Baseline & Audit: Assess data quality and identify major weaknesses.
- Add Observability: Monitor pipeline health, drift, and latency in real time.
- Establish Governance: Define ownership, lineage, and data contracts.
- Automate Validation: Integrate schema checks and test data into CI/CD flows.
- Adopt AI-Aided Reliability: Use AI tools for anomaly detection and root cause tracing.
- Institutionalize Continuous Improvement: Hold postmortems, educate teams, and embed reliability metrics in KPIs.
Reliability grows through iteration, one verified dataset, one automated check at a time.
Avoiding Common Pitfalls
Even well-intentioned reliability initiatives can backfire. Too much rigidity can hinder innovation, while excessive noise alerts can lead to fatigue. Privacy laws can limit observability, and the cost of maintaining reliability tools can be underestimated.
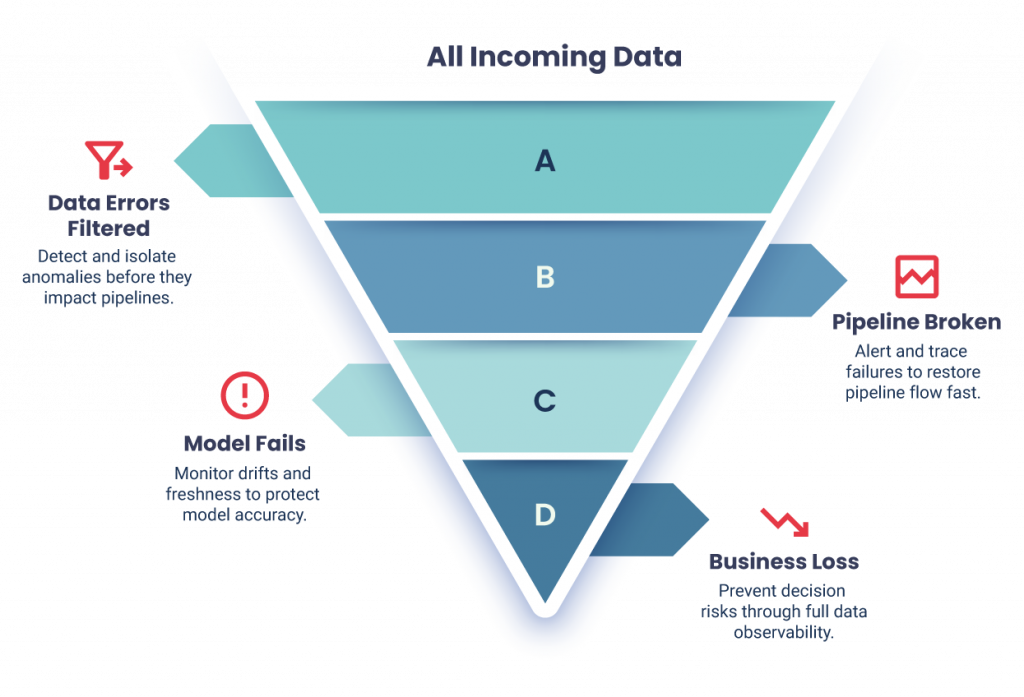
The biggest challenge, however, is cultural. Reliability only endures when teams value it as shared accountability, not a backend responsibility or a compliance checkbox.
The Bottom Line
In the era of generative AI, streaming data, and autonomous analytics in 2025, data reliability is essential.
Reliable data builds more than accurate predictions; it builds trust. It ensures that every decision, dashboard, and model output is grounded in truth, not assumption.
Organizations that treat reliability as a strategic asset, not an operational afterthought, will be the ones that thrive.If your analytics stack struggles with broken pipelines or drifting accuracy, connect with the Qualdo™ team.
We’ll help you instrument, monitor, and scale the invisible foundation that makes every prediction trustworthy, your data.