Data Observability, Data Quality, Data Reliability
What Is Data Reliability In Enterprise Analytics

Team Qualdo
25 Jul 2025
In the modern enterprise, analytics are only as strong as the quality of the data they’re built on. Yet as they scale their enterprise analytics, the complexity and risk of unreliable data multiply. What is required to establish a robust foundation for data-driven decisions at scale, particularly in light of the emergence of Agentic AI?
- Enterprise analytics is evolving rapidly, with Agentic AI driving key decisions and automation; however, most AI systems still rely on underlying data pipelines that are often unreliable.
- Incomplete, outdated, or inconsistent data quietly leads to poor forecasts, failed automations, and lost revenue.
- Data reliability is about building systems that:
- Monitor pipelines continuously
- Validate data automatically at every stage
- Track data lineage across tools and teams
- Enforce governance and compliance by design
- Monitor pipelines continuously
- Without this foundation, Agentic AI can amplify small data issues into large-scale failures. Reliable data is what transforms enterprise analytics from a risk into a genuine advantage.
Data Reliability is the Backbone of Scaling Analytics
As part of the data analytics team, you might be investing resources in business intelligence, dashboards, and Agentic AI for intelligent process automation, only to discover weeks or months later that crucial decisions were made based on outdated, duplicated, or incomplete data. With AI applications relying on vast, constantly shifting datasets, errors in source data can propagate, amplify, or even trigger unintended automated actions.
It’s more common than you’d think: enterprises routinely pay the price for data that lacks reliability, leading to missed opportunities, operational blunders, or outright regulatory violations.
In data & analytics, half of business decisions will be augmented or automated by AI agents by 2027, making data reliability foundational to AI governance, model accuracy, and compliance, according to Gartner.
Data reliability, in the context of enterprise analytics, refers to the accuracy, consistency, and timeliness of your information, ensuring it supports high-stakes decisions. As organizations scale, the stakes climb even higher:
- Business trust depends on it: One poorly timed reporting error can undermine confidence across business units.
- Costs escalate: Teams end up firefighting data problems instead of innovating.
- The business impact is real: From erroneous inventory restocking to regulatory fines, unreliable data gradually but relentlessly drains value.
Real-World Breakdown –
When Data Reliability Fails in Enterprise Pipelines
Take the case of a global e-commerce retailer struggling with inventory reconciliation. Unnoticed pipeline failures and mismanaged inputs from store-level systems resulted in dead stock in some regions and empty shelves in others, leading to millions of dollars in lost sales and wasted logistics. In short, unreliable data renders sophisticated analytics and emerging Agentic AI solutions ineffective.
Is Scaling Data Means Scaling Complexity?
As analytics programs grow, so do the challenges. Enterprises face a mesh of data sources, tools, and users, each creating new risk vectors.
Data Volume
Modern organizations process massive data volumes, petabytes per day, from IoT sensors, application logs, transactions, and other sources. Small inconsistencies can snowball into major analytical errors, and traditional manual checks are no longer sufficient to keep pace.
Data Variety
Analytics isn’t just about structured tables anymore. Now you’re wrangling API streams, log files, images, documents, even social feeds. Integrating these diverse formats, while maintaining consistency and meaning, is a growing challenge, especially when fueling Agentic AI systems that consume all types of data.
Data Velocity
With real-time dashboards and streaming analytics, data needs to be reliably clean at all times. A hiccup in a real-time pipeline can instantly ripple through executive reports, AI deployments, and machine learning models, with costly results.
Data Lineage
Do you know where your data originated and how it’s been transformed? Maintaining end-to-end data lineage, tracing every transformation and touchpoint becomes non-negotiable for both troubleshooting and regulatory compliance.

Principles for Reliable Data Analytics Architectures
To move beyond ad hoc fixes, leading organizations are investing in the core pillars of reliable data architectures:
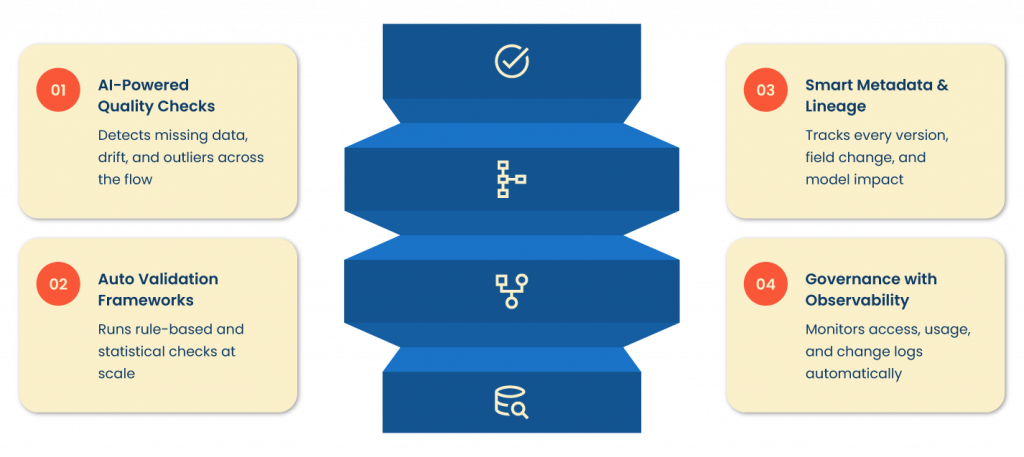
1. Data Quality Management
This begins with continuous monitoring, identifying anomalies, missing values, or outliers in real-time, before analysts and decision-makers encounter flawed results.
2. Automated Data Validation
Gone are the days of slow, manual checks. Rule-based and statistical validation engines operate at the speed and scale modern enterprises require, instantly flagging issues at the earliest point of data ingestion or transformation.
3. Metadata Management & Lineage
Comprehensive metadata, including dataset origins, schema versions, and data transformation logs, supports transparency, troubleshooting, and fast audits. Knowing exactly “where this number came from?” is vital, especially under regulatory scrutiny.
4. Data Governance and Compliance
With sensitive and regulated data, access controls, change logs, and usage audits must be tightly managed. Observability tools ensure the right people have the right access at the right time, nothing more, nothing less.
To improve your data quality, explore our guide, “A Data Quality Improvement Strategy for the 2025 AI Era,” for additional insights on data quality improvement strategies for scaling analytics in the AI Era.
Best Practices for Data Reliability as You Scale
What actionable steps should enterprise analytics teams pursue?
- Automate testing: Build frameworks for continuous, scalable automated tests that validate data at ingestion, transformation, and consumption points.
- Deploy real-time monitoring and alerting: Instead of waiting for users to spot problems, proactive monitoring catches issues as they happen.
- Make pipelines reproducible: Use version control for data and logic, so every step of every transformation is traceable and rollback-capable.
- Regularly audit lineage: Schedule periodic audits and visualizations of data lineage to identify risks and ensure compliance.
- Foster data stewardship: Assign clear ownership of critical datasets to business and technology stewards for accountability.
Choosing the Right Technologies & Tools
The ecosystem of data reliability solutions has experienced significant growth. Today’s best-in-class tools offer:
- Data quality monitoring with AI-driven anomaly detection, automated profiling, and deep integrations.
- Automated validation frameworks that can handle structured and unstructured data at scale.
- Powerful lineage visualization and tracking solutions to manage sprawling data pipelines and regulatory needs.
When evaluating data reliability solutions, look for true scalability, a deep feature set, compatibility with your existing stack, and the ability to automate (and ideally, learn from) your unique business patterns.
To gain a deeper understanding of the broader aspects, refer to Gartner’s “Data Quality: Best Practices for Accurate Insights” for a comprehensive market overview.
Looking Ahead – Advanced Strategies
- Cloud-native and hybrid environments introduce challenges and opportunities, such as flexibility, as well as new vulnerabilities for data inconsistencies across platforms.
- Machine learning and Gen AI-powered anomaly detection now enable detection of issues far earlier, learning what “normal” looks like in complex, fast-moving analytics.
- As the scale of analytics grows, so does the need for efficient storage, elastic compute, and lightweight automation to prevent operational bottlenecks.
Qualdo-DRX is an example of a solution built from the ground up for enterprise data reliability, weaving together monitoring, lineage, and modern AI-driven anomaly detection.
Data Reliability Is A Journey, Not a Destination
Building strong data reliability isn’t a one-time project. As data sources evolve, pipelines change, and analytics, including Agentic AI, grow more sophisticated, continuous improvement is essential. Enterprises that get this right innovate more quickly, build trust, and turn analytics into a true competitive advantage.
Take a Proactive Approach to Data Reliability at Scale.For organizations seeking robust, scalable data reliability solutions for enterprise analytics, explore how Qualdo.ai and its features can help you put these best practices into action and turn your data into a business asset you can truly rely on.