Machine Learning, ML Monitoring
The Trust Infrastructure Behind Enterprise AI in 2026

Team Qualdo
26 Feb 2026
What Is RAGOps?
RAGOps is the operational discipline that ensures retrieval-augmented AI systems remain accurate, reliable, and trustworthy over time, by treating retrieval and context as first-class production systems, not “supporting features.”
When GenAI Gets It Wrong, Data Is Usually to Blame
By 2026, most enterprise GenAI failures won’t come from models; they’ll come from retrieval.
Enterprises adopted Retrieval-Augmented Generation (RAG) to ground answers in internal knowledge and reduce the risk of hallucinations. OpenAI describes RAG as injecting external context into the prompt at runtime so the model can respond with more accurate, context-aware outputs.
But once RAG moves from demo to production, teams discover a harder reality: trust is operational, not theoretical. Data changes, pipelines break, embeddings go stale, and retrieval quality degrades quietly, until users stop believing the assistant.
That’s why RAGOps has emerged as the missing trust layer: the operational discipline that keeps retrieval, context, and generation accurate, observable, and reliable over time.
Why “Good RAG” Breaks in Production
A RAG demo often works because the dataset is small, the documents are fresh, and the query distribution is predictable. Production is the opposite: the corpus is alive, permissions are complex, and users ask messy questions that don’t resemble test prompts.
The Myth of “Set-and-Forget” RAG
RAG quality isn’t static; it decays.
A policy document gets updated, but the embedding is not regenerated. A schema change lands in a source system, but ingestion doesn’t fail loudly. A team migrates a knowledge base, leaving behind old URLs. None of these look like “AI problems,” yet the assistant starts answering confidently with incorrect or outdated context.
This broader “data readiness” issue is consistently showing up in enterprise AI outcomes. Gartner warns that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data, and stresses that AI-ready data is not “one and done,” but a continuous practice requiring ongoing investment in metadata, observability, and governance.
Common RAG Quality Failures Enterprises Face (2025–2026)
When teams investigate RAG incidents, the root causes usually cluster into a few failure modes:
Irrelevant retrieval: the vector store returns semantically similar, but operationally wrong, chunks, often because chunking strategy or metadata filters don’t match real usage.
Outdated embeddings: documents changed, but embeddings weren’t refreshed; the system “lies politely” with stale context.
Pipeline partial failures: ingestion silently skips records, or access controls aren’t applied consistently, creating coverage gaps.
Confident wrong answers: the model produces fluent text even when retrieval quality is low, because generation can’t reliably self-diagnose missing context.
The key insight is simple: if retrieval is wrong, generation will be wrong with confidence.
What RAGOps Manages
A 2025 research paper formalizes RAGOps as an extension of LLMOps, with a stronger focus on data management and continuous evaluation, given that external data sources are constantly changing. It also notes that RAG appears in a majority of enterprise LLM compound systems, which is exactly why operational rigor matters at scale.
Beyond the Model
RAGOps shifts responsibility from prompt tweaks to system integrity, governing:
- Source data freshness and validity
- Embedding generation, versioning, and refresh policies
- Retrieval accuracy, coverage, and failure detection
- End-to-end pipeline health (ingestion → processing → indexing → retrieval)
- Output trust signals (groundedness, citations/attribution, confidence, and abstention behavior)
This is why RAGOps is best described as trust infrastructure; it turns “AI answers” into something enterprises can monitor, debug, and audit.
The Core Pillars of RAGOps in 2026
The practical scope of RAGOps is larger than many teams expect. In mature deployments, it looks less like a single feature and more like a reliability layer spanning the entire GenAI stack.
Data Freshness and Lineage
Freshness is the first trust boundary.
If your source of truth updates but your embeddings don’t, the assistant can still retrieve confidently, just from the wrong snapshot. Mature RAGOps adds automated freshness checks tied to SLAs (for example: “product policy pages must be re-embedded within 6 hours of change”).
Lineage completes the trust loop: answer → retrieved chunk(s) → document version → source system. When a user asks “why did it say that?”, lineage provides a real engineering answer, not a shrug.
Embedding Quality and Drift Monitoring
Embeddings are not “generate once and forget.”
Over time, meaning shifts: product names evolve, internal acronyms change, teams reorganize, and query behavior becomes more diverse. Drift shows up as slowly worsening retrieval relevance, even though nothing “broke.”
RAGOps treats embeddings as versioned artifacts with measurable quality: you can A/B-test embedding models, track degradation, and trigger re-embedding workflows when drift crosses thresholds.
Retrieval Observability (Making Hallucinations Visible)
Most teams only monitor latency and token counts. That’s like monitoring a database by CPU usage and never checking query correctness.
RAGOps makes retrieval behavior observable. It answers questions such as:
- Which queries consistently retrieve low-relevance context?
- Which sources dominate answers (and should they)?
- Where are “holes” happening, topics that users ask about that the corpus doesn’t cover?
- Which filters or permission checks are causing unexpected zero-results?
Microsoft’s RAG evaluation guidance is notable here because it separates evaluation into retrieval relevance, response relevance, groundedness, and response completeness, and emphasizes that retrieval quality becomes a bottleneck that requires explicit measurement (with or without ground-truth labels).
Pipeline Reliability (DataOps for RAG)
RAG pipelines are multi-stage, and every stage can fail in ways that don’t look like failure.
Indexing jobs can partially succeed. Chunking can degrade quietly after a formatting change. Connectors can rate limit. Permission sync can lag. None of these necessarily crashes the app, yet they can corrupt trust.
RAGOps introduces automated detection and remediation so that bad context is prevented from reaching generation, and the system can degrade gracefully (abstain, ask clarifying questions, or route to a fallback).
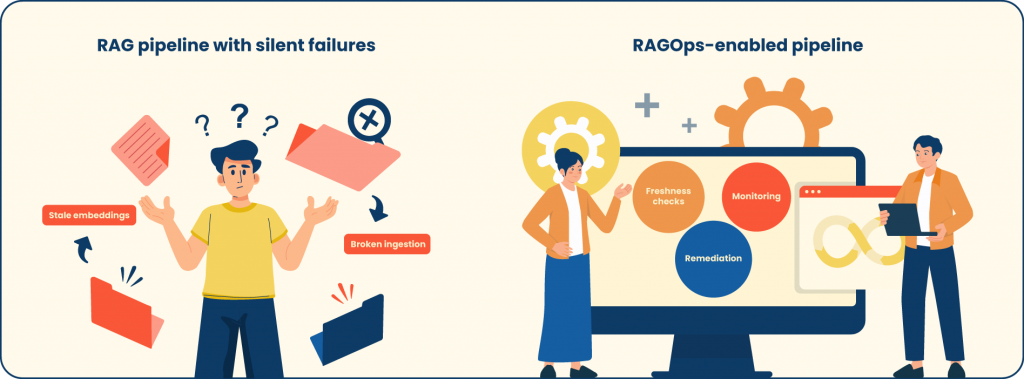
Why RAGOps Becomes Mandatory in 2026
RAGOps stops being a “nice to have” the moment GenAI becomes decision-adjacent: customer communication, employee policy guidance, pricing explanations, compliance interpretation, or operational troubleshooting.
Trust Becomes the Bottleneck
Enterprises don’t stop GenAI adoption because it’s expensive; they stop because they can’t trust it.
This aligns with broader AI execution data: Fivetran’s 2025 survey found 42% of enterprises said more than half of their AI projects were delayed, underperformed, or failed due to data readiness issues, and also highlighted the operational burden where many organizations spend the majority of engineering effort maintaining pipelines instead of enabling outcomes.
If your RAG can’t prove it’s fresh, complete, and grounded, users treat it as a toy, regardless of how good the model is.
Regulatory and Brand Risk (Auditability, Not Just Accuracy)
As transparency expectations rise, the question isn’t only “is the answer correct?” but also “can you explain and trace it?”
The European Commission’s AI Act transparency guidance emphasizes transparency obligations for certain AI systems and the need to reduce deception and foster trust, highlighting mechanisms like metadata identification, logging, and other techniques to support transparency.
RAGOps is how enterprises operationalize this in practice: lineage logs, versioned sources, access-controlled retrieval, and repeatable evaluations.
Scale Changes Everything
At a small scale, a smart engineer can manually refresh embeddings and spot-check outputs. At enterprise scale, hundreds of sources, thousands of documents, millions of chunks, and constant change, manual maintenance collapses.
RAGOps enables reliability automation: continuous evaluation, automated remediation, and measurable SLOs for truth.
RAGOps vs Traditional MLOps (Why MLOps Isn’t Enough)
MLOps optimizes models: training pipelines, deployment, monitoring for drift, and rollback.
RAGOps optimizes truth delivery: the quality of retrieved context and the integrity of the end-to-end system that constructs answers from enterprise knowledge.
In practice, RAGOps adds layers MLOps didn’t need to care about:
- document ingestion correctness
- chunking strategy health
- embedding refresh and version control
- retrieval quality metrics (not just model metrics)
- grounding checks and citation/attribution behaviors
That’s why many “MLOps-ready” organizations still struggle with RAG in production; the failure mode moved from model weights to the context supply chain.
The RAGOps Control Plane: What Mature Teams Actually Run
RAGOps becomes real when it’s implemented as a control plane with repeatable workflows, not an abstract checklist.
Metrics That Matter (Retrieval, Context, Answer)
A mature scorecard typically includes:
Retrieval metrics: Recall@K, nDCG, MRR, query-to-context relevance, coverage (“did we retrieve anything meaningful?”).
Context metrics: freshness lag, duplicate chunk rate, permission correctness, chunk quality indicators (length, structure, metadata completeness).
Answer metrics: groundedness (no fabrication beyond context), response relevance, completeness (recall aspect), and abstention correctness.
The important shift is this: teams stop debating whether the assistant “feels right” and start operating with measurable quality signals.
SLOs for Truth
In 2026, “AI SLOs” increasingly resemble reliability engineering:
- Freshness SLO: “95% of Tier-1 documents re-embedded within X hours of change.”
- Retrieval SLO: “nDCG above threshold for labeled golden queries.”
- Groundedness SLO: “<1% of sampled answers include claims not supported by retrieved context.”
- Coverage SLO: “<2% zero-hit retrieval for top intents; unknown intents routed to knowledge gap workflow.”
Testing and Release Gates (CI/CD for RAG)
RAGOps adds automated gates before you ship changes:
- Corpus tests: detect missing collections, permission drift, broken connectors
- Embedding tests: compare retrieval performance across embedding versions
- Retriever tests: evaluate new chunking or reranking parameters against golden sets
- End-to-end tests: generate answers and score groundedness + completeness
This is where RAG becomes a true production system: changes are validated before users experience degradation.
Security and Access Controls (Trust Includes “Who Can See What”)
Enterprise RAG must respect identity, permissions, and audit logs. It’s not just about correctness; it’s about ensuring retrieval never leaks restricted content into context.
RAGOps typically enforces:
- permission-aware indexing and retrieval filters
- secure connector policies and least-privilege access
- immutable audit logs for retrieval events
- redaction and PII policies aligned to governance standards
Trust breaks instantly when the assistant reveals something it shouldn’t, even once.
Real-World Enterprise RAGOps Scenarios
These scenarios are common because they map directly to where enterprises feel risk.
Case 1: Customer Support Knowledge Assistants
RAGOps detects that the assistant is retrieving policy pages that were updated last week but re-embedded months ago. The system auto-triggers re-embedding and flags “freshness lag” as the root cause, preventing repeat incidents.
Case 2: Internal Analytics Copilots
Retrieval observability shows that common finance queries pull semantically similar but irrelevant tables, producing misleading summaries. RAGOps updates metadata filters, adjusts chunking, and adds a golden query suite for recurring intents.
Case 3: Compliance and Policy Q&A
Lineage tracking allows the team to answer audit questions: which document version supported the response, whether the user had access, and what retrieval events occurred. This is increasingly aligned with transparency expectations in policy guidance.
Building RAGOps: Where Teams Start (Without Turning It Into a Multi-Year Project)
RAGOps is easiest to adopt in layers. The goal is to move from “RAG that works” to “RAG we can trust.”
Step 1: Instrument the Retrieval Layer First
Start with retrieval telemetry: top queries, hit rates, source distribution, low-confidence retrieval, and zero-result clusters. Without this, you are blind to the biggest failure mode.
Step 2: Add Freshness + Lineage (The Fastest Trust Win)
Implement document version awareness and answer traceability. The moment you can show “this answer came from this source version,” stakeholder trust improves.
Step 3: Create a Golden Query Set and Automate Evaluation
Even 100–300 representative queries can become a powerful early warning system. Tie evaluations to deployments and data refresh events.
Step 4: Automate Remediation Loops
Once you can detect stale embeddings or broken ingestion, automate the response: re-embed, backfill, rerun indexing, or route to an incident workflow.
The Future of RAGOps
By 2026, you’ll see three patterns become standard:
- RAGOps as a built-in layer in enterprise AI stacks, not an add-on
- Trust measured operationally (freshness, groundedness, coverage), not subjectively
- “Why is my RAG inaccurate?” turns into a solvable systems question, because RAGOps provides the telemetry, tests, and control loops to debug it
And as Gartner puts it, AI-ready data is not “one and done”; it requires continuous improvement in metadata, observability, and governance.
If AI is the brain, RAGOps is the memory you can trust, and the operational discipline that keeps enterprise GenAI honest.
RAGOps starts before the vector store: if the ingestion and freshness layer isn’t reliable, no evaluator can save you. This is the gap we focus on with Qualdo.ai.


