When your Ka-chings stop, you know your ML model has died.
Data scientists identify model failure when revenue ceases to flow in, response metrics decline or any of the tracked key metrics plummet. When conducting a postmortem on a failed ML model, uncovering certain characteristics and commonalities across all failures is inevitable. In this article, we’ll outline steps for performing a postmortem analysis on an ML model failure.
What could be the typical reasons for considering an ML model to have died?
- It could result from the model not functioning or being broken.
- It could become obsolete.
- The predictions generated by the models are as reliable as a random function.
In simpler terms, if the model is no longer useful or has become irrelevant in the ecosystem.
Let’s delve into examples to gain a deeper understanding of this scenario:
- A model designed to predict medical diagnosis outcomes consistently fails.
- A model intended to forecast user clickthrough rates in advertisements struggles to predict accurate outcomes in numerous cases.
- A model built to anticipate changes in stock values falters in most instances.
- A model created to predict user engagement with posts/articles falls short of expectations for many users.
- A model suggesting the next video to play provides largely irrelevant results.
- A model forecasting weekly sales across different product categories consistently exhibits significant prediction errors.
All of these outcomes are undesirable when a model is deployed in production and fails to meet expectations.
Quantification:
Reviewing the aforementioned statements, one can observe that they all raise concerns about the model’s performance quality. Initially, quality is a mere perception or reflection of user satisfaction.
However, to genuinely assess whether a model’s deterioration is sufficient to declare it deceased, quantifying changes in model performance is essential. Shifting from perceived indications of quality to observed and measured metrics that reveal the extent of performance decline is necessary.
Upon reviewing the highlighted portions in the above statements, such as consistently and in most cases, it becomes evident that they reflect perceived deterioration.
Instead, incorporating specific numbers and ratios, like a 45% failure rate or one-third of cases, offers a more insightful perspective on performance changes.
This approach enables us to analyze shifts in model performance concerning accuracy metrics like precision and recall.
- Across various time periods
- With diverse user groups
- Throughout different seasons
- Across varying input feature value ranges
- And more.
Once the model performance is quantified, the ideal approach involves comparing it against metrics from the training environment.
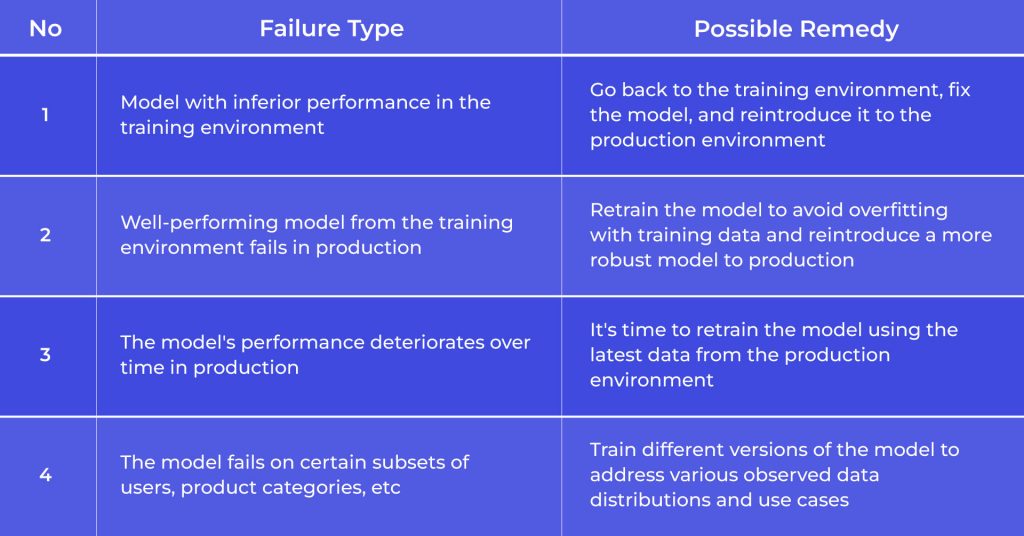
This methodology aids in identifying scenarios such as:
- A model with inferior training performance facing unrealistic production expectations
- A model excelling in the training environment but failing miserably in production
- A model initially succeeds in both training and production but later experiences decline
- A model performing well in production but faltering for specific user types or product categories
Each scenario necessitates a distinct approach.
Thus far, we have explored how to troubleshoot problematic models in production and address observed issues.
Training vs. Production Environment:
To offer a fair evaluation of a model and pinpoint its failure, comprehending the disparity between model training and the production environment is crucial.
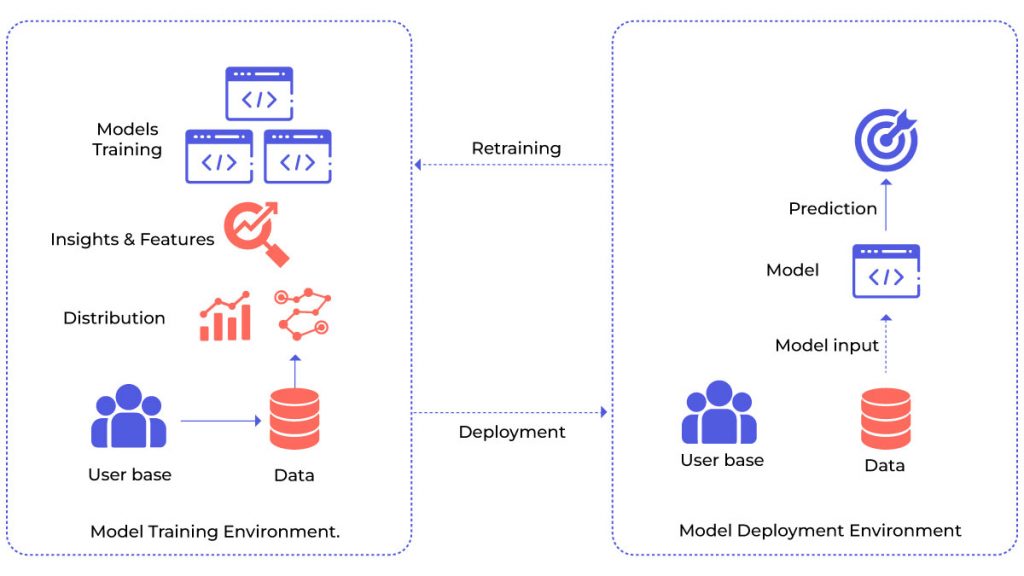
As depicted in the image above, the model training environment encompasses the following:
- A user base
- Generated and collected data points
- Distributions and patterns identified during exploratory data analysis Insights and features generated during the feature engineering phase
- Models trained using various techniques and feature combinations
The training process typically concludes by selecting the best model version based on observed performance metrics. Once the suitable model version is determined, it is deployed in the production environment.
But why does a model suddenly falter upon transitioning to production?
- As illustrated above, the production environment can witness:
- A complete shift in the user base Changes in user behavior, reflected in generated/collected data points
- Both scenarios indicate that the model encounters an entirely new output compared to its training phase.
Does this imply that the model is bound to fail upon encountering previously unseen data during training?
- Certainly not.
- The model should ideally perform reasonably well with unseen datasets.
- It serves as a litmus test for the model’s robustness.
- However, if the dataset distribution that the model learned from changes significantly, the model is expected to struggle.
For instance, consider a model forecasting weekly sales of certain product types:
- Trained with a specific price range that undergoes a complete shift in production
- A completely new user base with distinct purchasing behaviors enters the system
- Seasonal discounts lead to a substantial uptake of products
These changes significantly alter the operational conditions under which the deployed model functions.
Consequently, the model is likely to deteriorate and perform poorly in such scenarios.
Therefore, these situations demand a proper troubleshooting approach instead of making a sweeping statement like, “Oh, the model is dead, it’s useless!”
The following image summarizes potential troubleshooting steps to rectify a model perceived as failed.
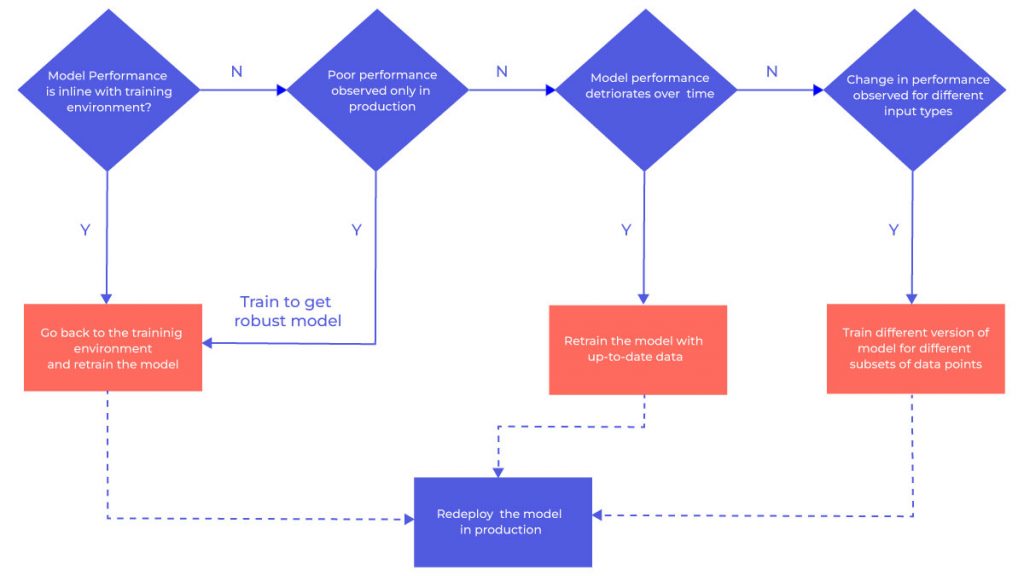
Key Questions:
The following set of questions aids in addressing issues related to model performance and failures:
- Is it related to Data Quality?
- Are there runtime performance issues affecting scoring latency and throughput?
- Have environmental changes occurred?
- Is data drift responsible?
Data Quality:
If the underlying data lacks quality, all other troubleshooting attempts regarding model training, deployment, etc., become irrelevant. Regardless of how sophisticated the model may be, if the data used is of poor quality, the resulting model outputs will reflect the same.
Ensuring high-quality input data is crucial for obtaining meaningful model outcomes. Data quality encompasses metrics such as data completeness, standardization, consistency, and accuracy. Analyzing these metrics can help correlate model failure with data quality.
Runtime Performance of Scoring:
Sometimes, addressing a model’s failure could involve optimizing the runtime performance of the deployed scoring function. For instance, if users experience prolonged wait times for model predictions, it could test their patience and impact user satisfaction.
Monitoring the latency of real-time predictions is vital for machine learning models deployed in such scenarios.
Additionally, if models operate in batch mode and predictions are delayed, the decay in prediction accuracy could result in response metric degradation. Monitoring scoring throughput is essential in these batch mode scenarios.
Environmental Changes:
Understanding factors contributing to changes in model accuracy against the training dataset is crucial when accuracy significantly drops. Such changes often indicate the need for model retraining and hyperparameter tuning. If accuracy remains high and prediction drift is minimal, but response metrics suffer, the focus should shift to the channels connecting predictions to consumers. Potential issues might arise from prediction delivery channels, message decay, or message content.
Data Drift:
While data quality metrics serve as high-level indicators for detecting ML model failures, the true indicators, if measurable, lie in data drift related to features or underlying data. Monitoring data attribute drift involves tracking statistical attributes of the same data points in a time series. Analyzing data drift of crucial attributes for an ML model can swiftly reveal the causes of model failure.
Conclusion:
Understanding the reasons behind an ML model’s failure can lead us down various paths, each of which may require substantial effort and time. Exploring available tools that shed light on mysterious cases of ML model failure reveals promising options for monitoring model decay, features, responses, and data quality. Qualdo™ seamlessly integrates Data Reliability with the essential forensics for comprehending ML model monitoring and decay.
Try Qualdo-MQX Today – www.qualdo.ai/mqx




