
The objective of this article is to provide an overview of what model drift means, and how we can measure and address the same.
Before we jump into the details, let’s start with a quick understanding of what model drift is. Model drift refers to the problem of decay of a model’s predictive power based on the changes occurring in the environment.
As we understand the model is trained with the given historical dataset and is moved into the runtime for prediction and scoring. Which is then getting integrated into a production system. What can possibly change in the environment that will impact the model and result in the decay of model performance?
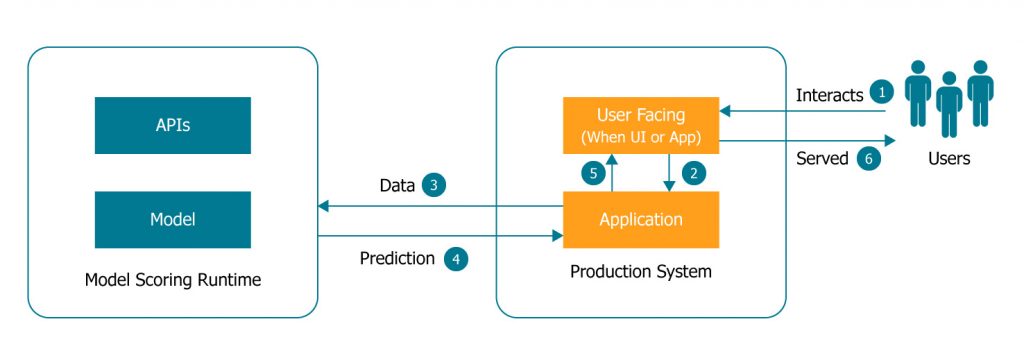
As can be seen in the picture above when a model scoring is served to the user through a production system.
- Some data points are captured from the users based on their interaction with the application, typically through an interface the application exposes
- Which the application collects and passes on in the form of data to the model
- The model will then return the prediction or score back the application
- Which will then be served the user
Why would the model drift?
This is kind of a typical setup of how the prediction from the model is served to the users. Let’s think about what kind of change can occur in the model scoring environment which could impact the model’s performance. Changes could be one of the following.
- Possible change in user base with new users
- Behavioral changes with the existing users
- Any changes in the system that could influence the users’ behavior significantly
- Any external features that the system is passing on during the model prediction/scoring
Hence any of these changes that may occur over time impacts the model performance. It can possibly result in the decay of the model’s predictive power.
Let’s understand a bit about why these factors impact the model performance.
Change in user base: When there is a considerable change in the user base, the historical data based on which the model was trained may not represent the new users added to the system. It would impact the model failing to perform well on some of these users.
Change in user behavior: Even when new users are added to the system, as long as they reflect the same kind of behavior like the user base on which the model was trained, it may not impact the model as much. But the moment the behaviors of the user base change considerably, the model performance will start decaying.
System changes: Any considerable changes in the system would have an inherent influence on the user behavior. For example, let’s say we are dealing with an e-commerce system, where we are trying to predict the user’s interest in various kinds of products in the inventory. In this case, when the type of inventory the system handles changes significantly or the e-commerce system starts offering significant discounts for specific categories, our models could start failing miserably. Much of the historical data points on which we have trained the model could become irrelevant or invalid.
External influence: Like the system changes, there could be a lot of external influence that would impact the change in user behavior. Some of these would have an implicit or explicit impact on user behaviors. Thus, impacting the models’ performance. For example, let’s say we have a model that predicts how much someone will spend monthly on entertainment. Factors like inflation, cost of living, etc. would result in lifestyle changes in the significant set of users. This means we will have to consider these changes and bring in necessary changes to the model based on the features we use.
What are the types of model drift?
As can be seen in the picture below there are two types of drift in general. Namely the concept and the data drift.
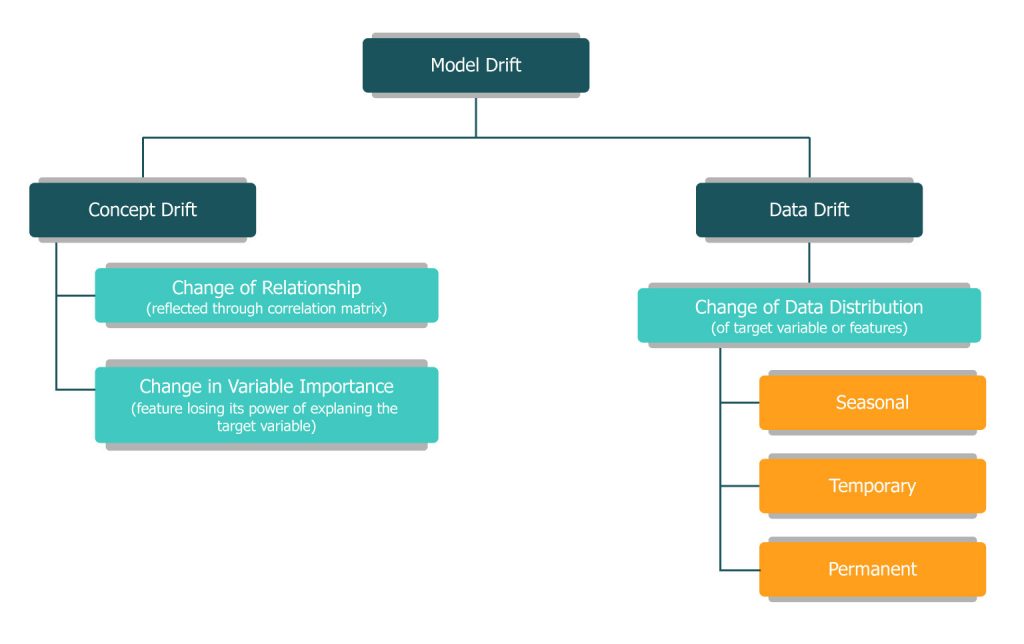
Concept drift:
Concept drift is about any inherent changes in the assumptions of the relationships based on which the model has been trained.
Change in relationship: We typically bring in a feature based on the correlation it shows with the target variable. As we looked at the previous section, any change in the user base or their behavior would impact these relationships of the features with the target variables. This type of concept drift is a reflection of any of these changes in the underlying system and/or the users.
Changes in variable importance: Some features that had a significant influence on the model’s predicting power may lose its ability to do the same. This might happen either because of the change in relationship or based on new possible features which we would have either ignored, not considered or not been aware of during the process of training the model. This is again a type of concept drift that we need to deal with.
Data drift:
Unlike concept drift the data drift would be explicitly visible when we look at the data. That is by looking into the distribution of the data, statistical measures (like mean, variance, etc.) and the outliers we can understand the presence of data drift.
The presence of data drift may or may not result in the concept drift. For example if the model is robust enough with a considerable set of features the data drift may not affect the model’s performance to start with.
Change of distribution: This can be spotted either by looking at the distribution visually or by comparing the changes in statistical measures like mean, median, variance, standard deviation, etc.
- Seasonal: The change we are noticing could be seasonal (weekend, month end, year-end, etc.)
- Temporary: The change could be a temporary one like we have looked at the impact of discounts on sales and user preferences.
- Permanent: The change could be a reflection of a permanent shift in the user behavior or the addition of users into the user base.
Based on the type of changes in the data, we can handle them accordingly.
What is model drift?
The next question that would come to our mind is on how we address the model drift. The easier and simplest answer would be to retrain and deploy the model again.
1. But we need to answer some of the following questions before we retrain and deploy the models.When do we retrain the model?
- This is where detection of model drift and understanding it helps
- The presence of a model drift provides an indication to us that the model needs to be retrained and deployed again
2. What do we change as part of the new model? It may not help us much if we just retrain the same model with additional data points. A study of the model drift would help us here as well in taking some of the calls on the aspects below.
- Add features
- Eliminate features
- Change of hyper parameters
- Change of model technique
3. How do we evaluate the model and test against the model in production? This may not be directly related to the study on the drift. But it is just a reminder to us that the process of studying drift should continue with the new models that get into the production
How to monitor model drift?
Without having a proper process in place to monitor model drift, we will not be able to identify the need for retraining the model and deploying again. Hence the process we put in here is crucial for us to study various types of model drifts and to trigger the steps required to address them accordingly.
For example, we can ignore the need for proactive monitoring of models altogether and decide to assess the model performance periodically (i.e., weekly, monthly, etc.). But by the time we assess and take remedial actions on retraining, the decay in the model’s prediction could have had a significant impact on the business.
Hence it is important for us to put model monitoring in place that can proactively identify and report model drift.
Please take a look at the follow-up article on this, which provides detailed guidance and an approach on how we can have a process of proactive and automated monitoring of model drift.
The best tool to monitor model drift
Qualdo helps enterprises to monitor mission-critical model performance & reliability metrics in production environments. With a few simple clicks, enterprises can automatically detect feature drifts, model decays and other performance metrics of importance to the model.
To know more about Qualdo-MQX, sign-up for a free trial.






