
Observability started with one job: to tell you when something broke. That job is no longer enough. The industry is moving toward something bigger – systems that don’t just detect problems, but prevent them. The shift has a name: autonomous reliability. And if you work with data, it’s coming for your stack whether you’re ready or not.
Here’s how we got here, and where things are going.
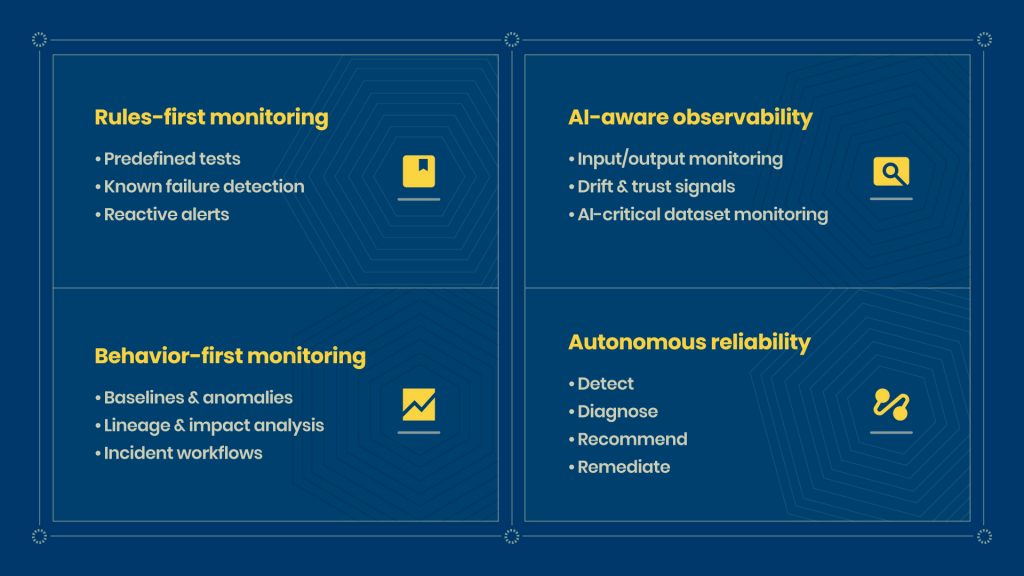
Era 1: Data Quality Checks (Rules-First)
The first generation of data reliability was simple. You wrote rules. If a column had nulls it shouldn’t; the check failed. If row counts dropped below a threshold, you got an alert.
It worked well for the predictable failures. The catch is that most failures aren’t predictable. A vendor silently changes a field name. A new pipeline writes duplicate records. An upstream job runs in the wrong timezone.
Rules catch what you already know to look for. They miss everything else.
Era 2: Data Observability (Behavior-First)
This is where the category really took shape. Instead of writing rules for every known failure, tools started learning what “normal” looked like for your data — row counts, schema patterns, freshness, distribution — and flagging when behavior drifted.
Lineage became part of the picture, too. Not just “this table has a problem” but “this table feeds these 12 downstream dashboards and three ML features.” Suddenly, you could answer the question your stakeholders were actually asking: what broke, and what does it affect?
The remaining gap was still the response. You got a good alert. You got a blast radius. The rest was still on you.
Era 3: Data + AI Observability (Stack-First)
AI workloads changed the requirements. When your data feeds a model, a silent schema change doesn’t just break a report — it corrupts training data or skews predictions in ways that are hard to catch and expensive to fix.
This era expanded observability to cover the full AI pipeline: monitoring inputs and outputs, catching drift, tracking trust signals, flagging when AI-critical datasets stopped behaving as expected.
If you run any kind of ML pipeline today, even a basic batch scoring job, this layer is not optional. The cost of bad data going into a model is much higher than the cost of bad data going into a dashboard.
Era 4: Agentic and Autonomous Ops (2026 and Beyond)
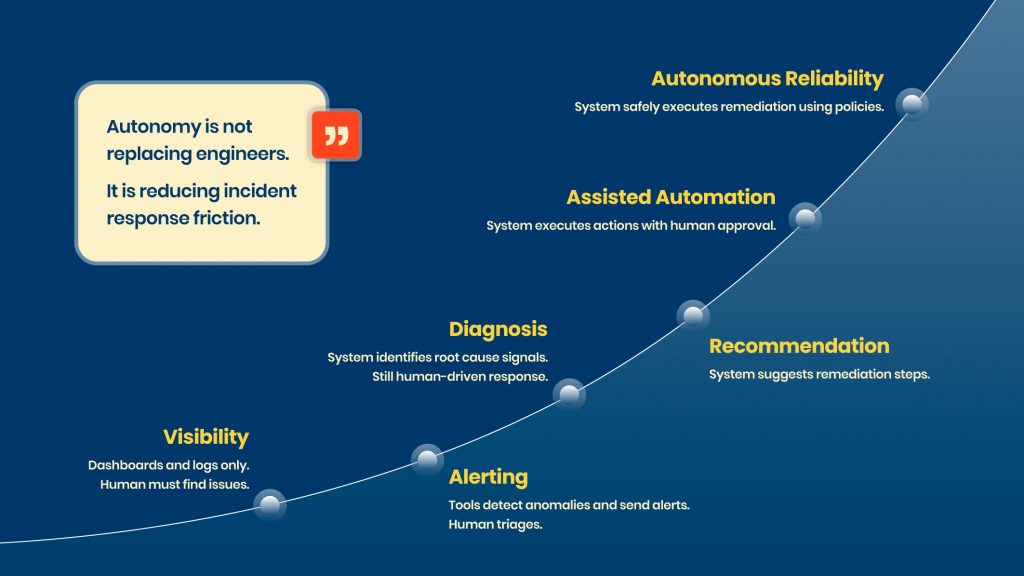
This is the era we are entering now. The shift is from alerting to controlled action.
Tools are starting to not just surface a problem but work through a full loop:
Detect. Diagnose. Recommend. Remediate.
A pipeline fails. The system identifies the root cause, suggests a fix, and — depending on how you’ve configured it — executes that fix automatically. Quarantine a bad partition. Trigger a backfill. Retry with corrected parameters. All with a full audit trail.
Vendors are already marketing around this explicitly. Acceldata calls it “Agentic Data Observability.” The race is on.
The important thing to understand is that “autonomous” does not mean “unsupervised”. The teams doing this well are building in governance from the start – approval gates for high-impact actions, RBAC, policy controls, evidence trails. The automation is only trustworthy if the guardrails are real.
What Buyer Expectations Are Shifting To
A year ago, the demo question was “how many anomalies can your tool catch?” That question is changing.
The new question is: how many incidents can you prevent? And can you prove it?
Dashboards and alert counts are no longer the metrics that matter. The metrics that matter are MTTR, how quickly you resolve an incident, and recurrence rate – how often the same problem recurs.
If your team is triaging the same pipeline failure every two weeks, your observability tool has not solved the problem. It has just made the problem visible faster.
What the Modern Stack Looks Like in 2026
A mature reliability stack sits in four layers above your data platform:
Observability layer. Monitoring, anomaly detection, lineage, usage analysis. This is table stakes.
Contract layer. Schema contracts, data SLAs, quality rules. Contracts are what make automation safe. You cannot auto-remediate a problem you have not defined.
Remediation layer. Retries, backfills, quarantine, runbooks. This is what converts observability from visibility into action.
Governance layer. RBAC, approval workflows, audit trails. This is what separates trustworthy automation from chaos. The vendors who get governance right will win. Not the ones who just automate the most.
What Comes Next
A few things are becoming clear about where this space is heading.
Autonomy will become a standard feature, not a differentiator. Every tool will claim agentic capabilities within 18 months. What will separate good implementations from bad ones is how well the policy controls are built — who can approve what, under what conditions, with what evidence.
Data contracts will stop being a best practice and start being a prerequisite. Automated remediation requires a clear definition of “correct.” Contracts are that definition. Teams without them will hit a ceiling on how far they can safely automate.
MTTR and recurrence rate will replace alert volume as the headline metrics. The conversation is already shifting in mature data orgs. If you are still reporting on how many anomalies you caught last month, you are measuring the wrong thing.
The future of observability is not visibility. It is reliability you can actually delegate.
See What This Looks Like in Practice with Qualdo
Qualdo is built for exactly this moment in the data stack. Whether your team is formalizing quality checks, building out lineage and anomaly detection, or exploring what governed automation looks like for your pipelines, Qualdo gives you the tools to move from reactive to reliable.
Less time fighting fires. More time building.
Talk to the Qualdo team and see how teams are cutting MTTR and building a reliability layer that their data and AI workloads can actually depend on.






